随着iOS 11的发布,苹果公司也正是加入到了机器学习的战场。在新的iOS 11中,苹果内置了CoreML机器学习框架,并完全支持iOS、watchOS、macOS和tvOS。苹果希望开发者使用这些框架来整合机器学习到他们的应用程序中,而不用去考虑框架是如何工作的。苹果还表示,开发者不必一定是机器学习工作者,相反,开发者只需要将训练好的模型使用其提供的工具转化为所支持的文件格式即可,不必考虑机器学习算法,只需要专注于应用程序的用户体验。
CoreML除了支持层数超过30层的深度学习之外,还支持决策树的融合、SVM、线性模型等,由于其底层建立在Metal和Accelerate等技术上,能够最大限度的发挥CPU和GPU的优势,因此在可以在移动设备上直接运行机器学习模型,数据可以不用离开设备直接被分析等。
苹果也在大力的宣传CoreML框架,在WWDC之后,有多个Machine Learning的session,基本上都是在介绍iOS中的机器学习该如何使用等最佳实践,从其session中可以看到目前iOS系统应用中已经有部分应用程序使用了机器学习,来提高应用程序的用户体验:
- 相册 — 场景识别、人类识别
- 键盘 — 智能响应、下一个字的预测
- Apple Watch — 智能响应、手写预测
- 相机 — 实时图像识别
- Siri — 智能分词、机器人
在构建机器学习的工程中需要两个步骤 — 训练和推理。
训练包括 — 学习算法,注意可能的行为和尽量在一个实体中收集所有的行为。在iOS机器学习情况下,苹果公司推出了MLModel的概念。模型将所有行为,属性,特征以及您认为的任何内容集合到一个实体中。
模型在这里起关键作用。 iOS中的机器学习不能没有模型,模型可以被认为是训练机器或代码的结果。模型由下一步可以使用的所有功能组成 - 推理。
推理包括 — 传递对象数据到模型,模型给出相应的结果,而这些结果将作为具体应用程序业务逻辑数据来使用。
这种训练和推理的过程更多的来自于实证方式,而不是纯理论的呈现。
苹果公司更加的希望开发者去进行推理而不是训练,训练是一个庞大的任务,并且会有很多的模型被贡献,开发者可以直接使用这些模型从而忽略训练的过程,直接进行推理并得到对应的结果来使用。
在WWDC session的视频讲座中介绍到,iOS的机器学习是一个分层的架构,顶层是用户直接体验机器学习结果的应用程序,在应用程序的底层有iOS机器学习的各类框架以供使用。
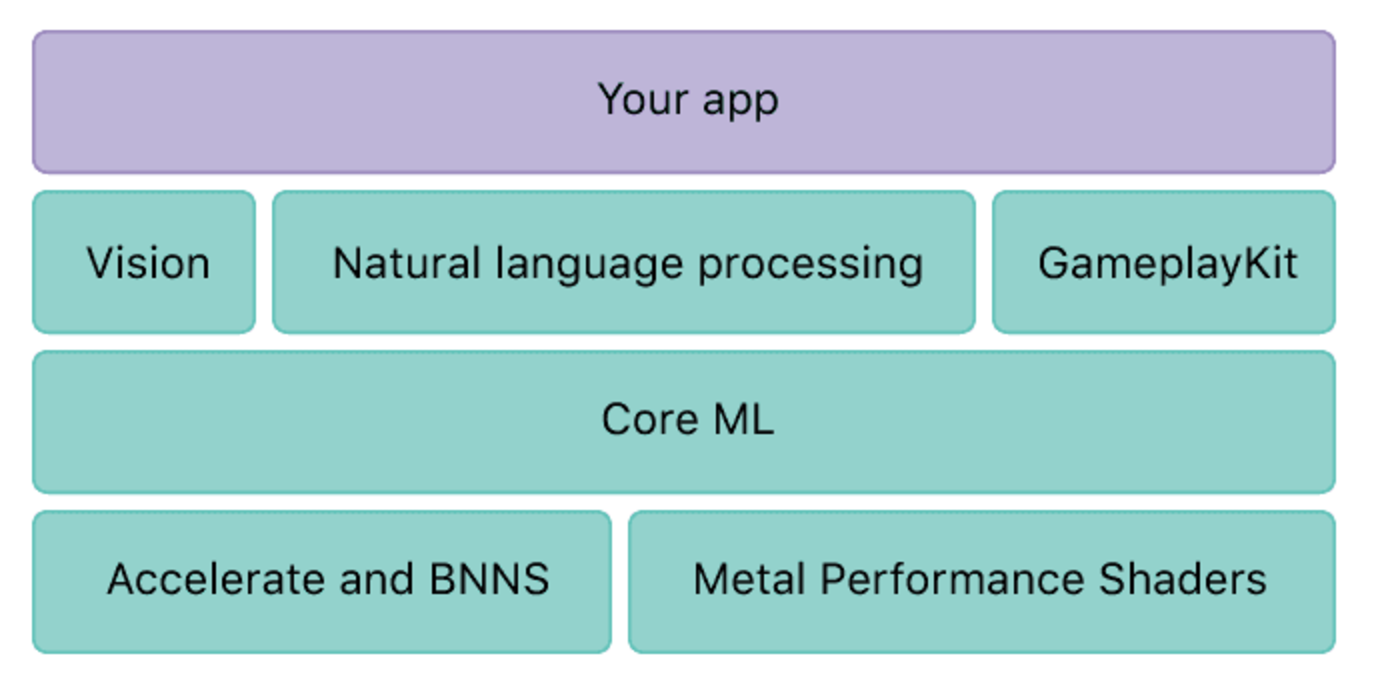
应用程序直接访问第二层 - Vision,NLP,GamePlayKit框架。 Vision用于处理图像,视频,音频 - 如人脸检测,跟踪对象等。NLP更多地依赖于文本处理,识别语言等。大多数基本机器学习功能可以使用这些特定于领域的框架来访问。而GamePlayKit通常用于游戏中的,当然在应用程序中也可以使用其相关的机器学习特性。
虽然有些功能不属于Vision,NLP这两个类别,但是可以使用第三层 - CoreML框架实现。 这也是苹果新增的一个框架,它是基础机器学习框架,涉及深度和标准的学习过程。 它以数字,文字,图像等的形式进行输入,可用于标注图像、实时视频描述等。
所有这些框架都建立在Accelerate和Metal框架之上,构成了第四层和最后一层。 这些可以在CPU或者GPU上进行数学运算,也可以用于创建自定义模型,使得硬件能够发挥其最大的性能。
说到模型,有各种各样的类型 — 预测文字,情感分析,音乐标签,手写识别,风格转移,场景分类,翻译等。MLModel支持树形组合,前馈神经网络,递归神经网络,广义线性模型,向量机,卷积神经网络等。 我们在哪里得到模型? 苹果在其网站上提供了4个模型等等。 为了方便开发者创建自己的定制模型,苹果还推出了模型转化工具CoreML Tools。
- 它是一个标准的Python包
- 将机器学习模型转化为MLModels
- 它有3层 — 转换器,CoreML绑定和转换库,以及CoreML规范
- 转换器 - 将模型从其他格式转换为CoreML接受的形式
- CoreML绑定 - 获取模型的Python包的预测和结果
- 转换器库 - 这是用于构建转换器的高级API
- CoreML规范 - 自己编写新模型。
接下来看看如何在应用程序中实现基本的机器学习功能。
我们的目标是使用Apple提供的Inceptionv3图像分类模型,分类图像并获得图像描述。
- 获取模型,并将其包含在应用程序中
- 进行相关的编码
当我们将模型添加进Xcode中并包含在当前工程后,Xcode便于自动识别模型为MLModel,并生成相应的类供调用。

该应用程序包含一个ImageView,描述该图像的Label以及一个选择图像的Button。

我们的目标使用逻辑伪代码表示如下:
let model = Inceptionv3()
if let prediction = try? model.prediction(image: image as) {//Make sure the image is in CVPixelBufferFormat
descriptionLabel.text = prediction.classLabel
} else {
descriptionLabel.text = "Oops. Error in processing!!"
}
在上述伪代码中,我们需要将UIImage转为CVPixelBufferFormat格式,但是这却比较的费劲,还记得上面提到过的Vision框架吗?其实Vision框架提供了相应的API供我们转化使用。
在开始之前,我们需要导入相关的框架:
import CoreML
import Vision
接下来需要一步步完成如下步骤:
- 使用
VNCoreMLModel获取模型类 - 通过提供的模型创建请求
request - 在Block回调中,使用请求响应,并从
VNClassificationObservation中获得结果 - 该结果数组中的第一个会给出与图像匹配最高的分类标签
代码如下:
func makePrediction(image: CVPixelBuffer) {
if let model = try? VNCoreMLModel(for: Inceptionv3().model) { // get the model
let request = VNCoreMLRequest(model: model) { [weak self] response, error in // create a request using the model
if let results = response.results as? [VNClassificationObservation], let topResult = results.first{
DispatchQueue.main.async { [weak self] in
self?.label.text = "\(topResult.identifier)\n\(Int(topResult.confidence * 100))% Sure"//Update the label
}
}
}
//The following is to perform the request
let handler = VNImageRequestHandler(ciImage: CIImage(image: imageView.image!)!)
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
} catch {
print(error)
}
}
}
}
主要的代码部分完成了,经过其他的完善,应用程序的表现如下:

