Caffe2是一个轻量级、模块化、可扩展的深度学习框架,它为移动端实时计算做了很多优化,并支持大规模的分布式计算。
Caffe2支持跨平台使用,既可以在云服务、Docker使用,也可以安装在 Mac、Windows或Ubuntu 上使用。同时也支持在 Visual Studio、Android Studio、和 Xcode 中进行移动开发。
Caffe2作为一个神经网络框架,具有以下优点:
- 支持最新的计算模型
- 分布式训练
- 高模块化
- 跨平台的支持
- 高效率
它为我们提供了模型搭建、训练和跨平台部署的能力。
深度学习应用
深度学习和神经网络可以用来处理很多问题。比如处理大数据集,实现自动化,图像处理,数据统计和数学运算等。

计算机视觉已经发展了很多年了,并且已经在一些比较先进的机器上进行应用了,比如一些制药设备。甚至还有车牌识别功能,可以自动为超速、闯红灯等行为开罚单。神经网络对计算机视觉应用有很大的提升。一些图像处理也正在应用中,比如识别图片中的内容。也有一些视频处理相关应用,用来自动场景分类和人脸识别。

苹果的Siri就用到了语音识别技术。它能够解析英语的多种口音,同时支持及多种语言。这些能力都是通过DNN、CNN和其他机器学习方法实现的。

聊天机器人一般是当在网站中点击“支持”链接时出现。它会根据提问者的问题自动进行回答。现在更多复杂的聊天机器人都是通过DNN实现,它们可以理解提问者的语义,并结合上下文给出更合适的回答,更接近与真人。

物联网也正在飞速发展,它一直伴随在我们的身边。通过智能家居可以区分来到家里的人是房主、客人或是不速之客,根据对应的环境可以产生不同的反应,如亮灯或警报灯。现在AWS已经有IoT平台并提供了这些能力。
![]()
翻译可以通过声音、文本或者图像识别。Caffe2 的教程中就展示了如何创建一个可以识别手写英文文本的基础神经网络,识别率超过95%,而且速度极快。

海关就使用过热成像处理技术来识别人们是否患有热病,以防止疾病扩散。医疗记录也可以通过ML或DNN处理来找到其中数据的关系。
了解 Caffe2
在集成 Caffe2 之前先对它做一个简单的了解
使用 Caffe2 时有三个要点:
- 选择合适的模型
- 初始化 Caffe2
- 向模型输入数据,并获得输出结果
重点对象:
- caffe2::NetDef 是 Google Protobuf 实例,其中包含了计算图和训练好的权重值
- caffe2::Predictor 由“initialization” NetDef 和 “predict” NetDef 两个网络构成的状态类,我们输入数据获取结果时使用的就是 “predict” NetDef
Library结构
Caffe2由两部分组成:
- 一个核心 library,由 Workspace、Blob、Net 和 Operator 类构成
- 一个算子库, 包含一系列的算子实现(比如卷积)
它是纯C++实现的,且依赖下面的 library:
- Google Protobuf(轻量版本,约300kb)
- Eigen(基础线性代数子程序库),有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。目前在ARM上 Eigen 是性能最好,运算最快的。
建议尽量使用NNPACK,因为它在ARM上优化了卷积。NNPACK 是 Facebook 开源的CPU高性能运算库。
Caffe2的错误和异常通常会被抛出为 caffe2::EnforceNotMet (继承自 std::exception)。
浅析Predictor
Predictor是一个状态类,通常是只被实例化一次来相应多次请求。
核心类Predictor的构造方法如下:
Predictor(const NetDef& init_net, const NetDef& predict_net)
两个NetDef类型的输入都是 Google Protocol Buffer对象,表示着上面描述的两个计算图:
- init_net 通常会做一系列操作,把权重反序列化到 Workspace
- predict_net 指定了如何为每个输入数据执行计算图
构造函数中做了:
- 构建 workspace 对象
- 执行 init_net,申请内存空间并且设置参数的值
- 构建 predict_net(把 caffe2::NetDef 映射到一个 caffe2::NetBase 实例(通常是 caffe2::SimpleNet))
注意:如果构造函数在一台机器上失败了(抛异常),之后每台机器都会失败。在导出 NetDef 实例之前, 需要先验证 Net 是否可以正确执行。
运算性能
从2012年起 Caffe2 就已经使用 NEON 为ARM CPU优化过了。ARM CPU 可能会比on-board GPUs性能更好(Caffe2的 NNPACK 在ARM CPU的实现在 iPhone 6s之前的设备会比Apple的 MPSCNNConvolution 表现要好)。
对于卷积的实现,建议使用 NNPACK,因为它比大多数使用 im2col/segmm 的框架的速度要快很多,不止2~3倍。
设置 OperatorDef::engine 为NNPACK的示例:
def pick_engines(net):
net = copy.deepcopy(net)
for op in net.op:
if op.type == "Conv":
op.engine = "NNPACK"
if op.type == "ConvTranspose":
op.engine = "BLOCK"
return net
对于一些非卷积的计算(主要是全连接层),我们还是需要使用 BLAS 库。比如在iOS上使用 Accelerate,在 Android 上使用 Eigen。
内存消耗
很多人担心Caffe2会大量消耗内存。虽然模型实例化和运行Predictor会消耗一些内存。但是所有的内存分配都和Predictor的Workspace实例有关,没有’static’内存分配,所以在Predictor实例被删除后就没有对内存的影响了。
AI Camera Demo 浅析
Caffe2 提供了 Android 平台的图像中物体检测的 Demo。打开应用后,应用会通过摄像头获取当前场景图片,并实时识别图片中的物体内容。Demo 中使用了训练好的模型,支持1000种物体的识别。从应用的角度看,识别物体的时间消耗越少越好,所以如果我们使用自己的模型时需要在精准度、范围、大小和运行速度之间权衡。
尝试编译并运行AI Camera Demo
Demo Github 地址: https://github.com/bwasti/AICamera
1. 首先使用 git 获取项目源码:
git clone https://github.com/bwasti/AICamera.git
git submodule init && git submodule update
cd app/libs/caffe2
git submodule init && git submodule update
2. 导入项目到 Android Studio 中:
如果项目中的 gradle 插件版本和本地如果不一致,则修改为一致后再导入

3. 关联本地 NDK:
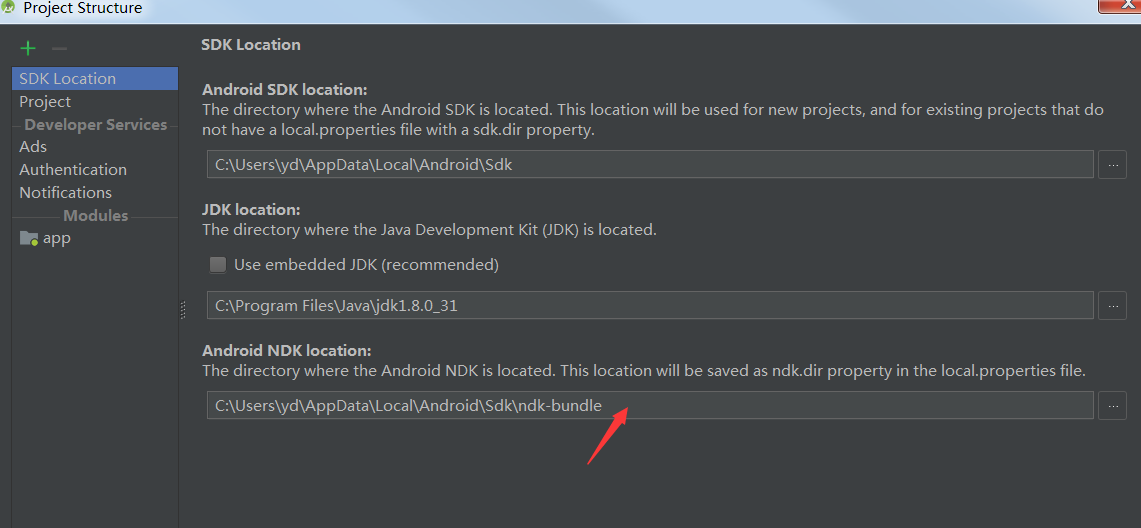
4. 编译运行后可以看到,应用正在识别拍摄到的物品:

Demo结构简析:
下图为从 Android Studio 中截取的 Demo 工程结构图
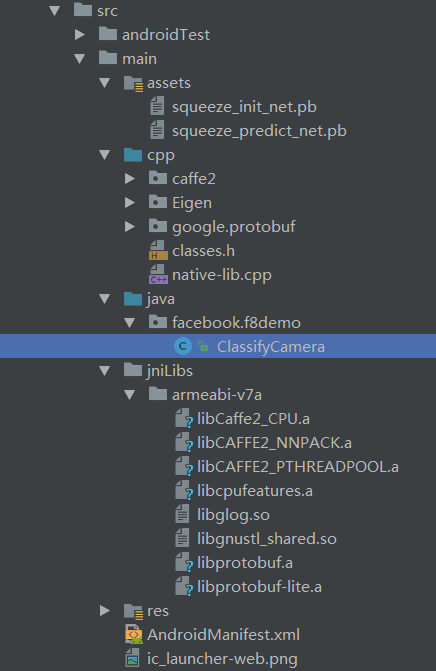
main/assets中的文件为模型文件,为 Protobuffer 格式main/cpp/caffe2为 caffe2 的C++源码库文件main/cpp/Eigen为一个高层次的C++库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法main/cpp/google/protobuf为 protobuffer源码main/cpp/classes.h为模型中的1000个识别种类对应的名称字符定义main/java/facebook/f8demo/ClassifyCamera.java为 Demo 中唯一的一个 Activity
ClassifyCamera 中提供了两个 native 方法:
//初始化资源模型等,传入的参数为AssetManager对象,用于加载assets中的模型文件
public native void initCaffe2(AssetManager mgr);
//输入原始数据,输出分类结果
public native String classificationFromCaffe2(int h, int w, byte[] Y, byte[] U, byte[] V,
int rowStride, int pixelStride, boolean r_hwc);
ClassifyCamera 在子线程中加载模型,初始化神经网络:
 **在 Java_facebook_f8demo_ClassifyCamera_initCaffe2 中分别加载了 squeeze_init_net.pb 和 squeeze_predict_net.pb,并初始化 Predictor 对象:**
**在 Java_facebook_f8demo_ClassifyCamera_initCaffe2 中分别加载了 squeeze_init_net.pb 和 squeeze_predict_net.pb,并初始化 Predictor 对象:**

从 CameraDevice.StateCallback 中获取到图像后,获取图片的参数,输入到 classificationFromCaffe2 方法中得到分类结果:
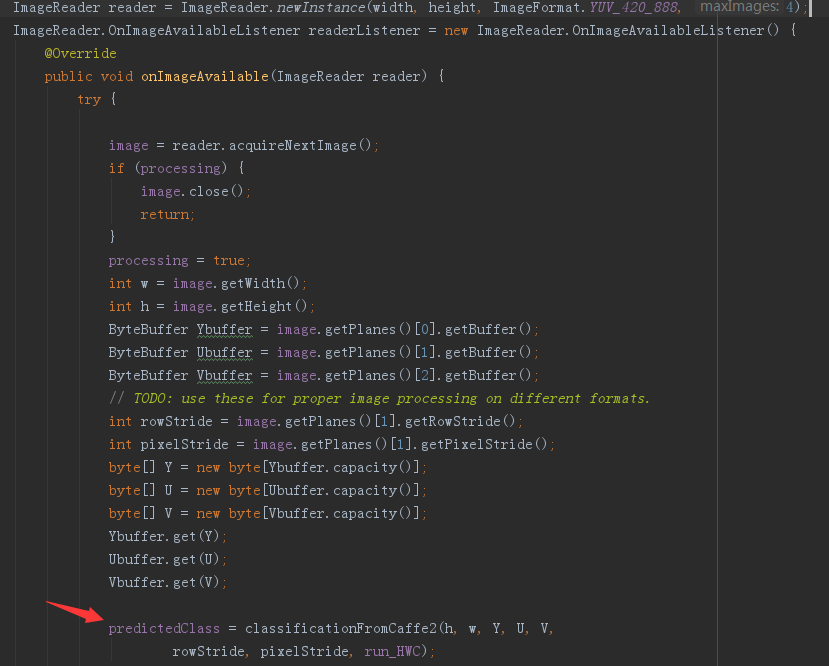
参数说明:
- h:图片高度
- w:图片宽度
- y:图片色彩y通道值
- u:图片色彩u通道值
- v:图片色彩v通道值
- rowStride:一行像素头部到相邻行像素的头部的距离
- pixelStride:一个像素头部到相邻像素的头部的距离
图片尺寸
Demo 中使用 Caffe2 处理图片时,图片需要是正方形的,所以即使从摄像头中获取到的图片不是正方形的,我们也需要把它裁剪成正方形。在 Demo 中,我们使用的图片尺寸是227*227。
图像格式
每个相机软件或硬件对色彩处理可能不同,所以我们需要统一一个标准后再传到Caffe2中使用。在Android Demo的代码示例中我们可以看到,图片在从色彩编码使用的是YUV,并传入了 classificationFromCaffe2 函数。但是在 classificationFromCaffe2 中,又把YUV格式数据转换为了RGB。因为 Android 中 CameraPreview 中的图像数据格式为YUV格式,但训练模型时使用的图片是BGR格式, 所以需要转换一下:
在Demo的 main/cpp/native-lib.cpp 中有详细代码,这里只给出部分代码:

上图步骤中有几个重点:
- 图片三通道的数据最终都合并到了一维数组 input_data 中
- b_mean、g_mean、r_mean 是从训练数据集图片中获取的B、G、R三通道的平均值, 在 Demo 中以硬编码方式呈现
- 最后从YUV转换格式转换为BGR后,还需要减去上面提到的平均值。这样在数据整体基本不变的前提下,减小了输入数据的值,会提高接下来的运算效率。
开始计算
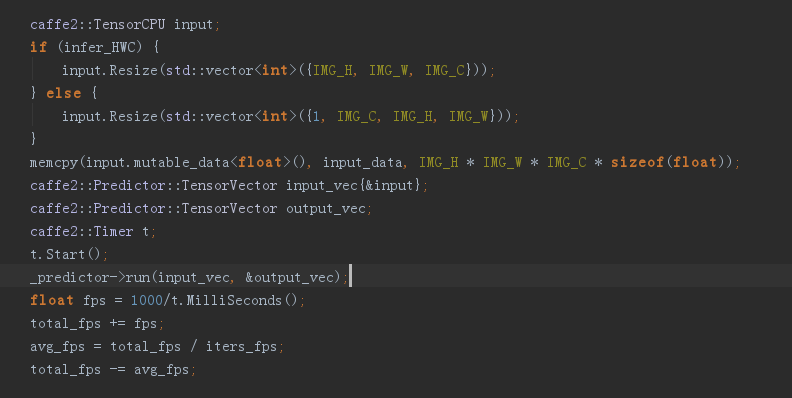
在获得了当前图像数据后(保存在了 input_data 数组中),我们就可以使用初始化好的 Predictor 对象来对当前图像进行计算识别了。
bool run(const TensorVector& inputs, TensorVector* outputs);
Predictor 的 run 函数需要两个参数,inputs为输入的转换后的图像数据,outputs 用于保存计算后的结果。执行 run 函数就会开始使用模型对输入数据进行计算。
Timer 用于记录计算消耗时间,根据消耗的时间可以计算出FPS值。
返回结果
执行 Predictor 的 run 函数后,计算的结果会保存在 output_vec 中。 其中通过计算得到的概率会保存在 max 数组中,对应的识别出来的物品的 index 会保存在 max_index 中, 通过 imagenet_classes 可以找到对应的识别出来的物品名称。Demo 中只取了识别率最高的5组结果。
把得到的结果和之前计算出的FPS值一起返回给 Android 应用层, 就可以显示在应用的界面中了。

这就是从使用者的角度对图像识别的过程的简单分析。
识别时可能遇到的问题
- 确认输入正确的图片
使用 Caffe2 时获取合适格式的图片是至关重要的,不这样做往往会引发一些问题。有时我们会认为输入的图片都是正确的,除了检测结果精准度低外,感觉没什么问题。如果看到的识别结果像“sand dunes”, “windowpanes”, “window blinds”之类的可能是因为输入的图像是损坏的,看起来像有很多横线的电视屏幕。虽然应用在正常运行,但这不是我们想要的结果。所以 Demo 会把输入模型中的图片同时输出到屏幕中,可以直观的确认图片的格式、比例等信息是否正常。
- 需要注意我们使用的是相机哪种模式?横屏还是竖屏?
图片中的物品有可能是斜着的,所以我们需要检查旋转并且确认我们正在使用哪种模式。这样我们才可以更准确的判断。
protected Matrix getMatrixFromCamera() {
int rotation;
if (getCameraId() == Camera.CameraInfo.CAMERA_FACING_FRONT) {
// Undo the mirror compensation.
rotation = (360 - mOrientation) % 360;
} else {
rotation = mOrientation;
}
Matrix matrix = new Matrix();
matrix.postRotate(rotation);
return matrix;
}
- 注意:如果使用的预先设置的尺寸过大,可能会超过摄像头的尺寸限制,而且还需要考虑存储的问题。
Caffe2 和 Caffe对比
Caffe 框架适用于大规模的产品用例,性能好,且有大量测试稳定的C++库。Caffe 有一些从原始用例继承来的设计上的选择:传统CNN应用。随着新的计算模式出现,比如支持分布式计算、移动端计算、降低精度计算和其他非视觉计算,Caffe 就有了很多限制。
Caffe2 对 Caffe1.0 做了一系列的升级:
- 优化大规模分布式训练
- 支持移动端部署
- 支持新的硬件
- 未来的趋势更灵活,比如量子计算
- 被 Facebook 大规模的应用压力测试过
- 模块化,可以更好地融入到业务逻辑中
总结
总而言之,Caffe2 是一个跨平台的新型工业级神经网络框架。我们在移动端,服务器端,物联网设备,嵌入式系统都能部署 Caffe2 训练的模型。我们期待在不就的将来,Caffe2 可以为通往AI的道路上创造新的阶梯,为我们带来不一样的惊喜。
