简介
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架,也是腾讯优图实验室成立以来的第一个开源项目。ncnn 从设计之初深刻考虑手机端的部署和使用,无第三方依赖,跨平台,手机端 CPU 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 App。ncnn 目前已在腾讯多款应用中使用,如 QQ、Qzone、微信、天天P图等。
腾讯优图实验室以计算机视觉见长,ncnn的许多应用方向也都在图像方面,如人像自动美颜、照片风格化、超分辨率、物体识别。深度学习算法要在手机上落地,现成的 caffe-android-lib 依赖太多,而且手机上基本不支持cuda,需要又快又小的前向网络实现。单纯的精简 caffe 等框架依然无法满足手机 App 对安装包大小、运算速度等的苛刻要求。ncnn 作者认为,只有全部从零开始设计才能做出适合移动端的前向网络实现,因此从最初的架构设计以手机端运行为主要原则,考虑了手机端的硬件和系统差异以及调用方式。
腾讯优图ncnn提供的资料显示:对比目前已知的同类框架,ncnn是 CPU 框架中最快的,安装包体积最小,跨平台兼容性中也是最好的。以苹果主推的 CoreML 为例,CoreML 是苹果主推的 iOS GPU 计算框架,速度非常快,但仅支持 iOS 11 以上的 iPhone 手机,落地受众太狭窄,非开源导致开发者无法自主扩展功能,对开源社区不友好。
ncnn与同类框架对比
| 对比 | caffe | tensorflow | ncnn | CoreML |
|---|---|---|---|---|
| 计算硬件 | cpu | cpu | cpu | gpu |
| 是否开源 | 是 | 是 | 是 | 否 |
| 手机计算速度 | 慢 | 慢 | 很快 | 极快 |
| 手机库大小 | 大 | 较大 | 小 | 小 |
| 手机兼容性 | 好 | 好 | 很好 | 仅支持 iOS |
功能概述
-
支持卷积神经网络,支持多输入和多分支结构,可计算部分分支
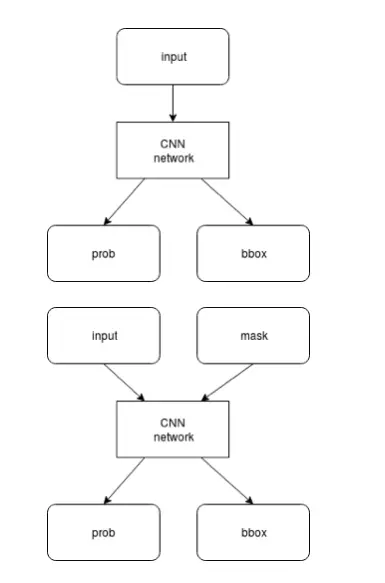
ncnn 支持卷积神经网络结构,以及多分支多输入的复杂网络结构,如主流的 VGG、GoogLeNet、ResNet、SqueezeNet 等。计算时可以依据需求,先计算公共部分和 prob 分支,待 prob 结果超过阈值后,再计算 bbox 分支。如果 prob 低于阈值,则可以不计算 bbox 分支,减少计算量。
-
无任何第三方库依赖,不依赖 BLAS/NNPACK 等计算框架
caffe-android-lib+openblas ncnn boost、gflags、glog、lmdb、openblas、opencv、protobuf 无 ncnn 不依赖任何第三方库,完全独立实现所有计算过程,不需要 BLAS/NNPACK 等数学计算库。
-
纯 C++ 实现,跨平台,支持 Android、 iOS 等
ncnn 代码全部使用 C/C++ 实现,跨平台的 cmake 编译系统,可在已知的绝大多数平台编译运行,如 Linux、Windows、Mac OS、Android、iOS 等。由于 ncnn 不依赖第三方库,且采用 C++ 03 标准实现,只用到了 std::vector 和 std::string 两个 STL 模板,可轻松移植到其他系统和设备上。
-
ARM NEON 汇编级良心优化,计算速度极快

ncnn 为手机端 CPU 运行做了深度细致的优化,使用 ARM NEON 指令集实现卷积层、全连接层、池化层等大部分 CNN 关键层。对于寄存器压力较大的 armv7 架构,手工编写 neon 汇编,内存预对齐,cache 预缓存,排列流水线,充分利用一切硬件资源,防止编译器意外负优化。
测试手机为Nexus 6p,Android 7.1.2。
-
精细的内存管理和数据结构设计,内存占用极低

在 ncnn 设计之初已考虑到手机上内存的使用限制,在卷积层、全连接层等计算量较大的层实现中,没有采用通常框架中的 im2col + 矩阵乘法,因为这种方式会构造出非常大的矩阵,消耗大量内存。因此,ncnn 采用原始的滑动窗口卷积实现,并在此基础上进行优化,大幅节省了内存。在前向网络计算过程中,ncnn 可自动释放中间结果所占用的内存,进一步减少内存占用。
内存占用量使用 top 工具的 RSS 项统计,测试手机为 Nexus 6p,Android 7.1.2。
-
支持多核并行计算加速,ARM big.LITTLE CPU 调度优化
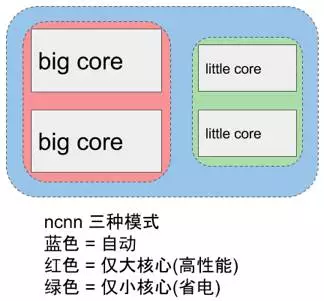
ncnn 提供了基于 OpenMP 的多核心并行计算加速,在多核心 CPU 上启用后能够获得很高的加速收益。ncnn 提供线程数控制接口,可以针对每个运行实例分别调控,满足不同场景的需求。针对 ARM big.LITTLE 架构的手机 CPU,ncnn 提供了更精细的调度策略控制功能,能够指定使用大核心或者小核心,或者一起使用,获得极限性能和耗电发热之间的平衡。例如,只使用1个小核心,或只使用2个小核心,或只使用2个大核心,都尽在掌控之中。
-
整体库体积小于 500K,并可轻松精简到小于 300K
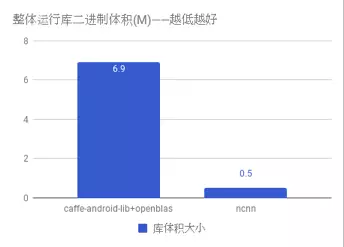
ncnn 自身没有依赖项,且体积很小,默认编译选项下的库体积小于 500K,能够有效减轻手机 App 安装包大小负担。此外,ncnn 在编译时可自定义是否需要文件加载和字符串输出功能,还可自定义去除不需要的层实现,轻松精简到小于 300K。
-
可扩展的模型设计,支持 8bit 量化和半精度浮点存储,可导入 caffe 模型
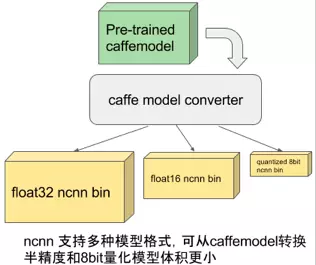
ncnn 使用自有的模型格式,模型主要存储模型中各层的权重值。ncnn 模型中含有扩展字段,用于兼容不同权重值的存储方式,如常规的单精度浮点,以及占用更小的半精度浮点和 8bit 量化数。大部分深度模型都可以采用半精度浮点减小一半的模型体积,减少 App安装包大小和在线下载模型的耗时。ncnn 带有 caffe 模型转换器,可以转换为 ncnn 的模型格式,方便研究成果快速落地。
-
支持直接内存零拷贝引用加载网络模型
在某些特定应用场景中,如因平台层 API 只能以内存形式访问模型资源,或者希望将模型本身作为静态数据写在代码里,ncnn 提供了直接从内存引用方式加载网络模型的功能。这种加载方式不会拷贝已在内存中的模型,也无需将模型先写入实体的文件再读入,效率极高。
-
可注册自定义层实现并扩展
ncnn 提供了注册自定义层实现的扩展方式,可以将自己实现的特殊层内嵌到 ncnn 的前向计算过程中,组合出更自由的网络结构和更强大的特性。
注:只包含前向计算,因此无法进行训练,需要导入其他框架训练好的模型参数。
框架设计

框架设计与caffe、EasyCNN基本类似,以Blob存储数据,以Layer作为计算单元,以Network作为调度单元。与前2者稍有不同的是ncnn中还有一个Extractor的概念,Extractor可以看做是Network对用户的接口。Network一般单模型只需要一个实例,而Extractor可以有多个实例。这样做的好处是进行多个任务的时候可以节省内存(模型定义模型参数等不需要产生多个拷贝)。
实践
ncnn功能测试
GitHub 上有可以直接运行的 Demo 工程,可以直接在 Android、iOS 上运行测试。
网址:https://github.com/dangbo/ncnn-mobile
运行效果如下:

在 Mac 上编译安装 ncnn
- 下载编译源码 访问项目主页:https://github.com/Tencent/ncnn ,使用 git 下载项目
:
git clone git@github.com:Tencent/ncnn.git -
安装依赖环境:
cmake: brew install cmake: protobuf: brew install protobuf -
开始编译:
cd ncnn mkdir build && cd build cmake .. make -j make install -
编译成功在控制台输出:
Install the project... -- Install configuration: "release" -- Installing: /Users/liudawei/worksapace/github/ncnn/build/install/lib/libncnn.a /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: /Users/liudawei/worksapace/github/ncnn/build/install/lib/libncnn.a(opencv.cpp.o) has no symbols -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/blob.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/cpu.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/layer.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/layer_type.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/mat.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/net.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/opencv.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/paramdict.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/layer_type_enum.h -- Up-to-date: /Users/liudawei/worksapace/github/ncnn/build/install/include/platform.h进入ncnn/build/tools目录下查看生成的工具:
liudawei@localhost ~/worksapace/github/ncnn/build/tools master ll total 728 drwxr-xr-x 5 liudawei staff 170B 12 7 17:11 CMakeFiles -rw-r--r-- 1 liudawei staff 7.7K 12 7 16:39 Makefile drwxr-xr-x 8 liudawei staff 272B 12 7 17:12 caffe -rw-r--r-- 1 liudawei staff 1.3K 12 7 16:39 cmake_install.cmake drwxr-xr-x 6 liudawei staff 204B 12 7 17:12 mxnet -rwxr-xr-x 1 liudawei staff 351K 12 7 17:17 ncnn2mem # caffe模型的转换工具(caffe2ncnn)位于 caffe 目录下 XXXX@localhost ~/worksapace/github/ncnn/build/tools/caffe ls CMakeFiles caffe.pb.cc caffe2ncnn Makefile caffe.pb.h cmake_install.cmake # mxnet模型的转换工具(mxnet2ncnn)位于 mxnet目录下 XXXX@localhost ~/worksapace/github/ncnn/build/tools/mxnet ls CMakeFiles 4Makefile cmake_install.cmake mxnet2ncnn由于 ncnn 不支持模型训练,需要将其他训练好的模型做转换导入。本文中以 caffe 为例。
-
将 caffe 模型转换为 ncnn 模型:
XXXX@localhost ~/worksapace/github/ncnn/build/tools/caffe ./caffe2ncnn new_deploy.prototxt new_bvlc_alexnet.caffemodel alexnet.param alexnet.bin -
去除可见字符串 有 param 和 bin 文件其实已经可以用了,但是 param 描述文件是明文的,如果放在 App 分发出去容易被窥探到网络结构(使用 ncnn2mem 工具转换为二进制描述文件和内存模型,生成 alexnet.param.bin 和两个静态数组的代码文件):
ncnn2mem alexnet.param alexnet.bin alexnet.id.h alexnet.mem.h -
加载模型
-
直接加载 param 和 bin,适合快速验证效果使用:
ncnn::Net net; net.load_param("alexnet.param"); net.load_model("alexnet.bin"); -
加载二进制的 param.bin 和 bin,没有可见字符串,适合 App 分发模型资源:
ncnn::Net net; net.load_param_bin("alexnet.param.bin"); net.load_model("alexnet.bin"); -
从内存引用加载网络和模型,没有可见字符串,模型数据全在代码里头,没有任何外部文件 另外,Android apk 打包的资源文件读出来也是内存块:
#include "alexnet.mem.h" ncnn::Net net; net.load_param(alexnet_param_bin); net.load_model(alexnet_bin);以上三种都可以加载模型,其中内存引用方式加载是 zero-copy 的,所以使用 net 模型的来源内存块必须存在。
-
-
卸载模型
net.clear(); -
输入和输出
ncnn 用自己的数据结构 Mat 来存放输入和输出数据输入图像的数据要转换为 Mat,依需要减去均值和乘系数:
#include "mat.h" unsigned char* rgbdata;// data pointer to RGB image pixels int w;// image width int h;// image height ncnn::Mat in = ncnn::Mat::from_pixels(rgbdata, ncnn::Mat::PIXEL_RGB, w, h); const float mean_vals[3] = {104.f, 117.f, 123.f}; in.substract_mean_normalize(mean_vals, 0);执行前向网络,获得计算结果:
#include "net.h" ncnn::Mat in;// input blob as above ncnn::Mat out; ncnn::Extractor ex = net.create_extractor(); ex.set_light_mode(true); ex.input("data", in); ex.extract("prob", out);如果是二进制的 param.bin 方式,没有可见字符串,利用 alexnet.id.h 的枚举来代替 blob 的名字:
#include "net.h" #include "alexnet.id.h" ncnn::Mat in;// input blob as above ncnn::Mat out; ncnn::Extractor ex = net.create_extractor(); ex.set_light_mode(true); ex.input(alexnet_param_id::BLOB_data, in); ex.extract(alexnet_param_id::BLOB_prob, out);获取 Mat 中的输出数据,Mat 内部的数据通常是三维的,c / h / w,遍历所有的 channel 获得全部分类的分数:
std::vector<float> scores; scores.resize(out.c); for (int j=0; j<out.c; j++) { const float* prob = out.data + out.cstep * j; scores[j] = prob[0]; } -
某些使用技巧 Extractor 有个多线程加速的开关,设置线程数能加快计算ex.setnumthreads(4); Mat 转换图像的时候可以顺便转换颜色和缩放大小,这些顺带的操作也是有优化的 支持 RGB2GRAY GRAY2RGB RGB2BGR 等常用转换,支持缩小和放大
#include "mat.h" unsigned char* rgbdata;// data pointer to RGB image pixels int w;// image width int h;// image height int target_width = 227;// target resized width int target_height = 227;// target resized height ncnn::Mat in = ncnn::Mat::from_pixels_resize(rgbdata, ncnn::Mat::PIXEL_RGB2GRAY, w, h, target_width, target_height);Net 有从 FILE* 文件描述加载的接口,可以利用这点把多个网络和模型文件合并为一个,分发时能方便些,内存引用就无所谓了:
$ cat alexnet.param.bin alexnet.bin > alexnet-all.bin #include "net.h" FILE* fp = fopen("alexnet-all.bin", "rb"); net.load_param_bin(fp); net.load_bin(fp); fclose(fp);
-
使用ncnn的example
-
修改CMakeList.txt文件,去掉下面注释:
#add_subdirectory(examples) -
使用 make -j编译ncnn后,进入ncnn/example目录执行:
./squeezenet test.jpg -
输出结果:
333 = 0.586699(hamster) 186 = 0.053623 (Norwich terrier) 78 = 0.041748 (tick)测试图片:

附录:
Caffe 编译
-
下载编译源码,访问项目主页:git@github.cm:BVLC/caffe.git 使用 git 下载项目
git clone git@github.com:BVLC/caffe.git -
安装依赖环境
使用 Homebrew 安装所需要的其它依赖,其它依赖有gflags、snappy、glog、hdf5、lmdb、opencv3、boost、leveldb 、protobuf。通过 pip 安装 pycaffe。
-
开始编译
在 GitHub 上下载 Caffe 源码,地址为:https://github.com/BVLC/caffe,下载后在 Caffe 根目录创建 build 文件夹,将 Makefile.config.example 文件名改为 Makefile.config,修改 Makefile.config 文件。
$ vim Makefile.config然后修改里面的内容,找到如下内容:
# CPU-only switch (uncomment to build without GPU support). CPU_ONLY := 1 # CPU-only switch (uncomment to build without GPU support). CPU_ONLY := 1s# CPU-only switch (uncomment to build without GPU support). # CPU_ONLY := 1 # CPU-only switch (uncomment to build without GPU support). # CPU_ONLY := 1 去掉注释,修改后如下:执行 make -j,看到下面的内容说明安装 Caffe 成功。tools 目录下生成需要的升级工具:
XXXXX@localhost ~/worksapace/github/caffe/build/tools master ll total 1536 drwxr-xr-x 16 liudawei staff 544B 12 7 17:45 CMakeFiles -rw-r--r-- 1 liudawei staff 27K 12 7 17:45 Makefile -rwxr-xr-x 1 liudawei staff 135K 12 7 17:49 caffe -rw-r--r-- 1 liudawei staff 13K 12 7 17:45 cmake_install.cmake -rwxr-xr-x 1 liudawei staff 52K 12 7 17:49 compute_image_mean -rwxr-xr-x 1 liudawei staff 84K 12 7 17:49 convert_imageset -rwxr-xr-x 1 liudawei staff 39K 12 7 17:49 device_query -rwxr-xr-x 1 liudawei staff 88K 12 7 17:49 extract_features -rwxr-xr-x 1 liudawei staff 43K 12 7 17:49 finetune_net -rwxr-xr-x 1 liudawei staff 43K 12 7 17:49 net_speed_benchmark -rwxr-xr-x 1 liudawei staff 43K 12 7 17:49 test_net -rwxr-xr-x 1 liudawei staff 43K 12 7 17:49 train_net -rwxr-xr-x 1 liudawei staff 44K 12 7 17:49 upgrade_net_proto_binary -rwxr-xr-x 1 liudawei staff 44K 12 7 17:49 upgrade_net_proto_text -rwxr-xr-x 1 liudawei staff 44K 12 7 17:49 upgrade_solver_proto_text -
升级 Caffe 模型
liudawei@localhost ~/worksapace/github/caffe/build/tools ./upgrade_net_proto_text deploy.prototxt new_deploy.prototxt liudawei@localhost ~/worksapace/github/caffe/build/tools ./upgrade_net_proto_binary bvlc_alexnet.caffemodel new_bvlc_alexnet.caffemodel模型下载:
http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel
https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet
参考内容
https://github.com/Tencent/ncnn
https://github.com/Tencent/ncnn/wiki
http://blog.csdn.net/best_coder/article/details/76201275
